Checking environment after migration NSX V to T and cleanup
Earlier I wrote a post on the migration between NSX for vSphere (NSX-V) and NSX-T (https://my-sddc.net/migrate-nsx-for-vsphere-to-nsx-t/) . I stopped after the migration was complete because the post was long enough already and promised to come back with an article on the environment and clean up afterward.
This is that article as you might have expected ;).
Checking and repairing the environment
So, after the migration, I found out a couple of things that I had to “repair”. They are all related to “bad preparation”, so no real big issues.
I had to connect the created Edge Nodes to the correct networks. And since I am using nested hosts and multiple tagged and one untagged VLAN on my physical host, I also needed to change the VLAN segment that was created for the uplink interfaces of the new NSX-T environment.
After I had done all that, the uplink interfaces (that were automatically created by the input I gave during the migration) were reachable.
What did strike me as odd at first though, was that the “old” IP-Address from the uplink-interface on the ESG (in my case ending in .253). In hindsight, this isn’t really odd at all, since the old ESG is still running on the old environment, so to avoid an IP-conflict, new addresses needed to be put in (in this migration I was asked for these addresses and put in .61 and .63).
It deserves pointing out that since I was running my ESG’s on the same cluster as where the workloads were running, so on the same distributed switch, there was no real risk of an IP-conflict, but in a larger environment, with dedicated Edge-clusters, this might be an issue. So important to take into account that after the migration, the IP-address will be something to look into.
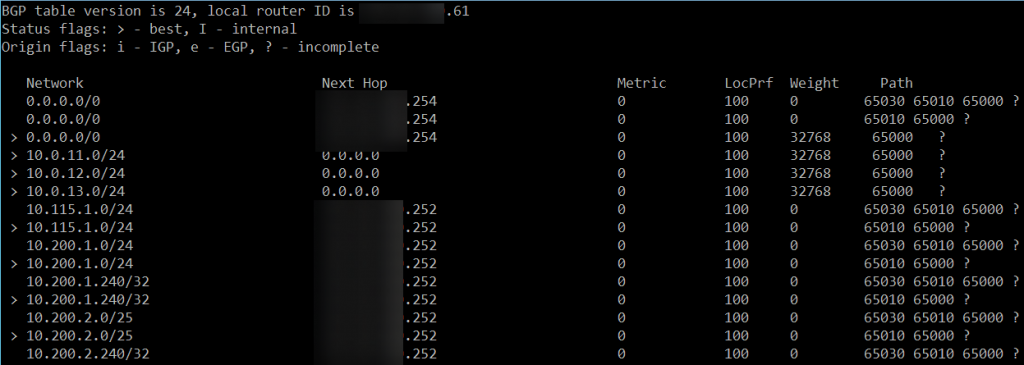
Important to note is that the BGP connection on the northbound router was still pointing to the old ESG, which means that routing to the VM’s that were connected to the new T-segments, were unreachable.
After I changed the BGP configuration for the different components, all was well:

and the forwarding table on the Edge Node showed the correct routes.
So after all this was done, time to do some clean-up.
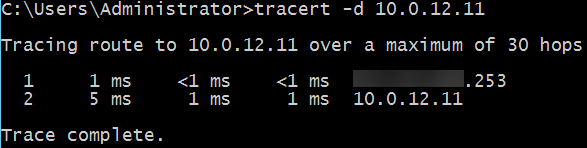
First of all, since we are doing some static routing from the internal network, I had to reinstate the IP-address that was used on the ESG in the V environment, ending in .253. So I changed one of the interfaces (.63) to this address and was able to reach it again. Then I changed the BGP configuration to connect to the .253 instead of the .61 and BGP was functioning like it was before the migration.
So I am also able to reach the VM’s that are behind the .253 gateway on the (now Geneve-based) overlay network:
Basically, all configurations that were in the V environment have been moved over to the T environment. We have one T0, connecting everything:

including all existing VXLAN’s (now Segments):

We got some segments that were distributed port groups for the functionality of vSphere itself:

After the network was doing what it should be doing, time to clean-up the old NSX-V environment.
Clean Up
First off we go and look at the status of the NSX for vSphere environment.
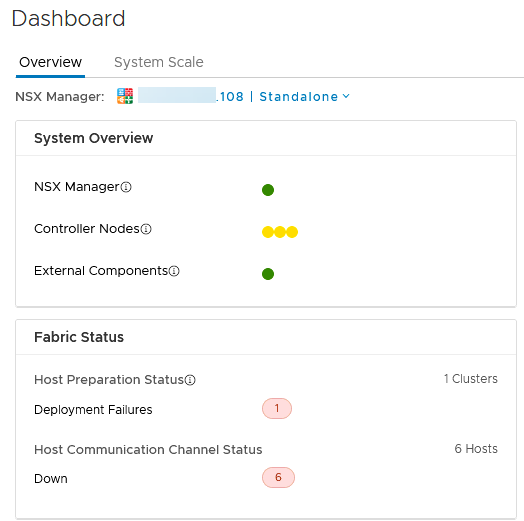
This is as expected. The NSX Manager has not yet been told that it was made redundant by a new NSX-T Manager, so the fact that it isn’t communicating with the hosts means it thinks something is wrong.
We can now remove the NSX stuff from the environment. This is described in: https://docs.vmware.com/en/VMware-NSX-T-Data-Center/2.5/migration/GUID-EA433FE8-6B7F-4D35-A454-9B41B1B24003.html
I am not going to demonstrate the exact steps I performed, I followed this manual and it is pretty self-explanatory.
After all steps are taken, we can remove all (now unused) distributed switches (just make sure they are not used ;)):

You might run into an issue where there are still some connections to the distributed switch. This might occur if you have snapshots that were connected or if you use templates. In my case, I had one template that I had to change in order to clean up one of the distributed switches.
Conclusion
Okay, so what about this migration? I have to say I do like the way it was able to do the migration with a minimum amount of downtime. Would I use it for a (large-scale) production environment? Hmmm, to be honest, I might choose a different path, if the option is available. Preferably through the use of additional hardware, build a new T environment besides the V environment and move workloads, but if you don’t have the budget or if there are other circumstances preventing you to do this, it might be a viable solution. But (as with a lot of stuff in IT) preparation is key!
Hope you found this useful, from now on I will be completely on T, so no more V for me :).
One thought on “Checking environment after migration NSX V to T and cleanup”