vSphere 7 and VCF 4.0: evolution or revolution?
When looking at the new version-numbers of both products, you might think, “a major update, but going further along an already well-trodden path”.
Well, you would think wrong. The newest additions to VMware’s SDDC portfolio do have new features and functions (and lots of them), but they are also very much changing things around and giving customers the possibility to focus on the technology that is taking the world by storm.
Modern Applications
So terms like DevOps and Modern Applications are not new. It means changing around the way you develop your applications into micro-services, which gives great flexibility, scalability and more “ility’s”, but one of the main issues there has been that developers need to do some operations and/or operators need to do some development. This is because both worlds need each other, but are not very used to each other’s realm.
When using traditional virtualization and applications, operators of virtual infrastructure create virtual machines and hand them over to developers to do their business. But for a couple of years developers are more and more moving towards microservices and containers. In order to use this in an effective and efficient way, a container-orchestration platform like Kubernetes is used more and more. However, where developers are very much used to working with Kubernetes, operators are not. On the other hand, operators are used to working with the infrastructure that runs all this code, but developers are not.
For me, the greatest new functionality of vSphere 7 and VCF 4.0 is the ability to give both worlds the tools and functionality they need. Operators can run their virtual infrastructure, the way they are used to, while at the same time developers are talking to a Kubernetes Namespace but both are using the same underlying resources:
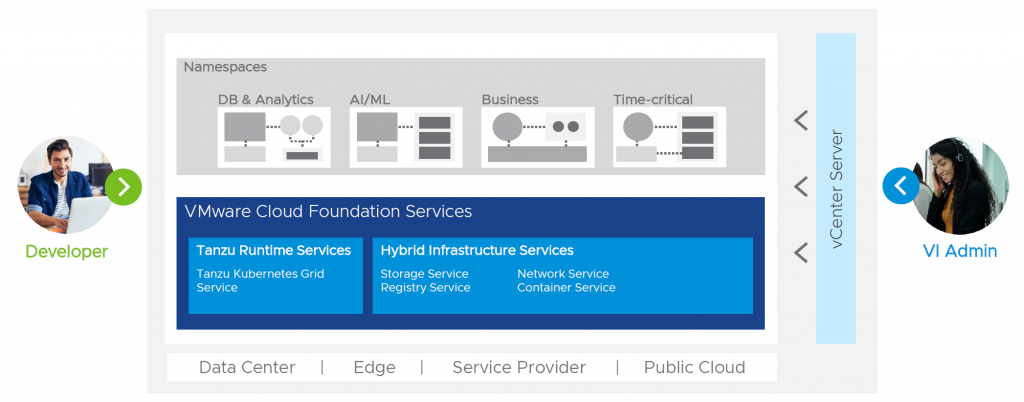
Kubernetes Namespaces can run directly on vSphere but the namespaces are being served by (very specially designed) virtual machines that an operator can control with all the tools they are used to.
To use this, you do need VMware Cloud Foundation (VCF). This is the heart of the solution and will unlock the potential of vSphere with Kubernetes. Reason for this is that in order to use this efficiently, you need the complete stack to support it, including network virtualization with NSX.
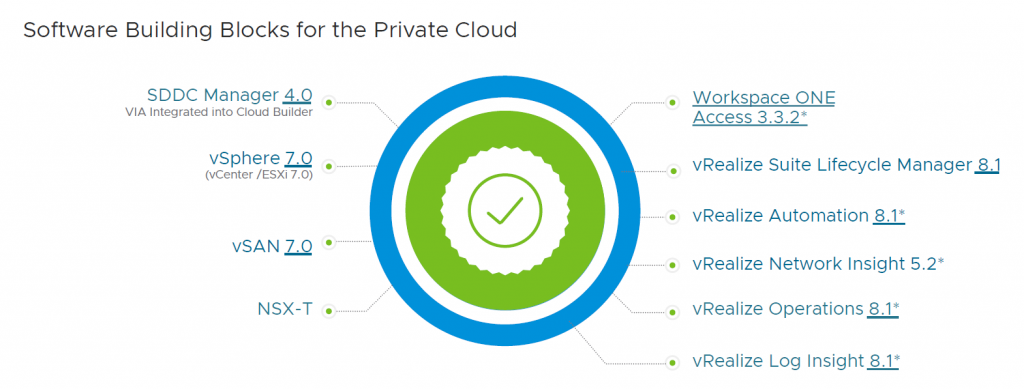
VCF 4.0
The new version of VCF includes a lot of new versions of the underlying software. Another big change is the fact that it now only contains NSX-T, so NSX for vSphere has been deprecated:
vSphere 7: New and Improved
Okay, but what if you are not focussed on modern applications and DevOps and stuff? Well, the new version of vSphere holds a few nuggets for you too. Some very exciting stuff coming your way. A couple of them are described below:
vSphere Lifecycle Manager
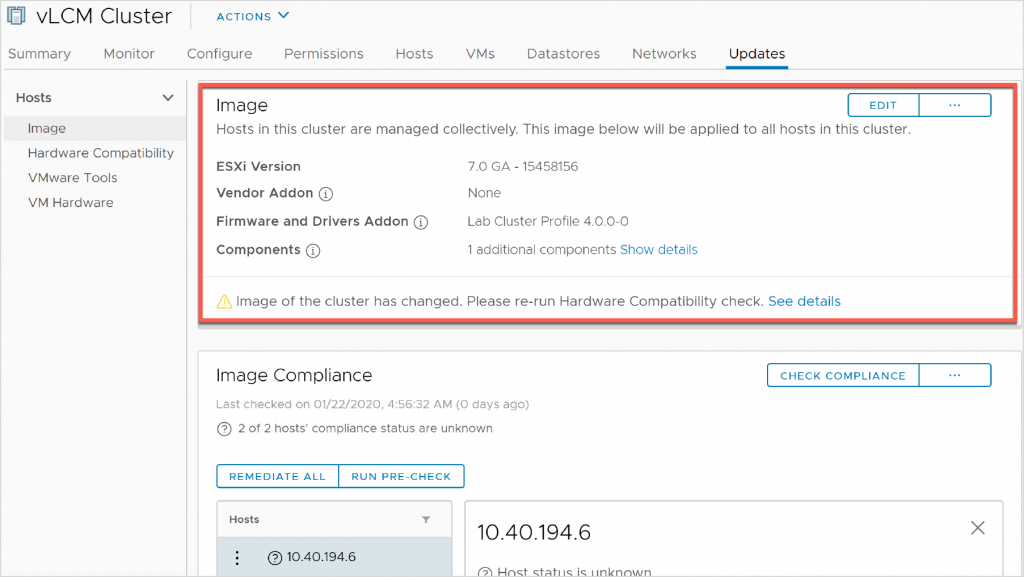
One of the things I am very excited about is the vSphere Lifecycle Manager. We have been using VMware Update Manager for a while now (I remember it’s announcement during VMworld Europe 2008 ;)), but the world has changed a little in the meantime. With vSphere Lifecycle Manager it becomes possible to manage your hosts based on “desired state” configuration. And not just the installed VIB’s or version of the kernel, but (with selected vendors, firstly Dell and HPE) also firmware and BIOS of the underlying hardware.
In order to do this efficiently, you can create an image, consisting of:
- Base Image
- Drivers
- Firmware + BIOS
- Vendor Plugins
When the image is done, you can apply it to a cluster and if needed monitor and remediate drift and/or update to new versions.
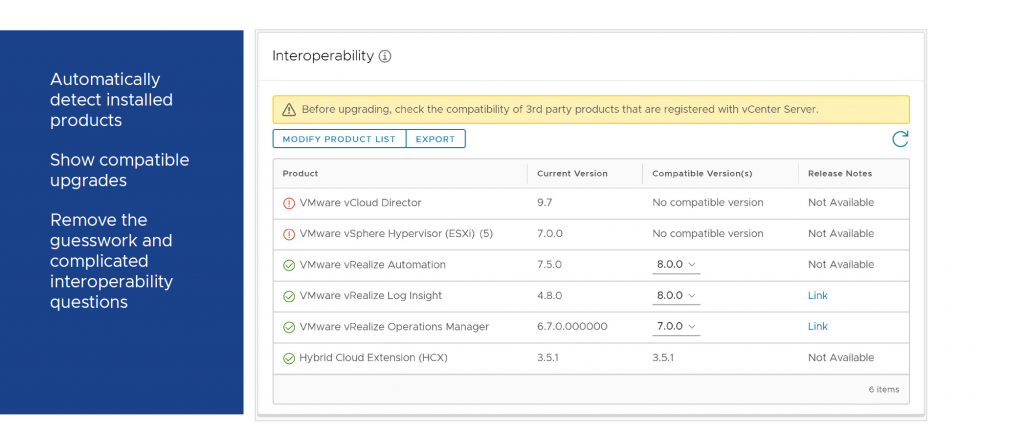
Update Planner
When doing an upgrade of an environment, it is necessary to look into all products that are used and if they interoperate with the newest version. For this you can use sites like: https://www.vmware.com/resources/compatibility/sim/interop_matrix.php. But with the new vSphere, this is included in the process. Update Planner gives you insight into the products that your are using and if this is compatible with the upgrade you are performing ór which version you need to be on, to be supported:
Distributed Resource Scheduler
DRS has been around for some time, but the world has changed considerably and the way DRS did it’s work was not always addressing the needs of the business. So DRS has been completely revamped. The functionality of getting information about optimizing the workloads is still there, but the method it uses has changed. In the new DRS multiple metrics are used to determine if it is advisable to move a virtual machine to another host, or not.
One of the things that is changed (and I really love this change) is the ability to use “scalable shares” within DRS. For everyone using shares and resource pools, this has always been a little bit of a nightmare, because shares are all relative to siblings, be it another resource pool or a virtual machine. In the following picture the old situation is shown:
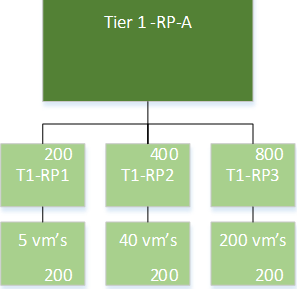
In this example, the virtual machines in the different resource pools would have to compete for resources available to that resource pool. So the virtual machines in T1-RP3, would have high shares, but since they are large in number (200) these 800 shares they are given lead to (effectively) four shares per virtual machine, while virtual machines in the (low shares) resource pool T1-RP1, would get 40 shares per virtual machine.
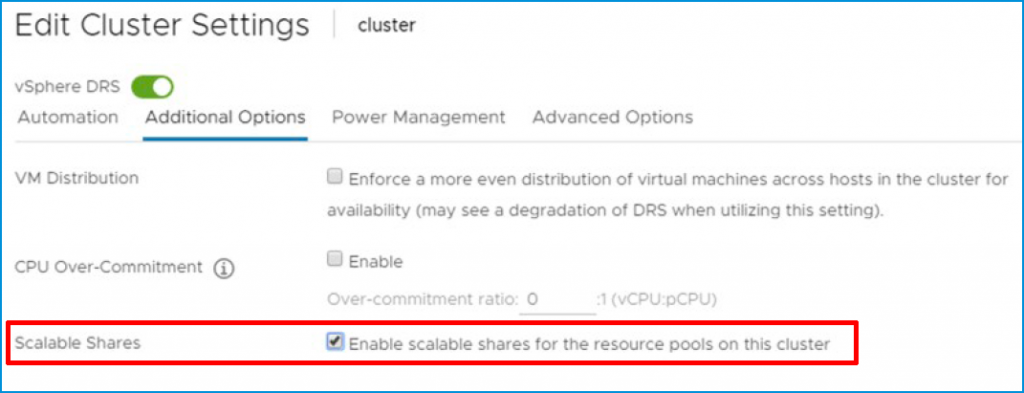
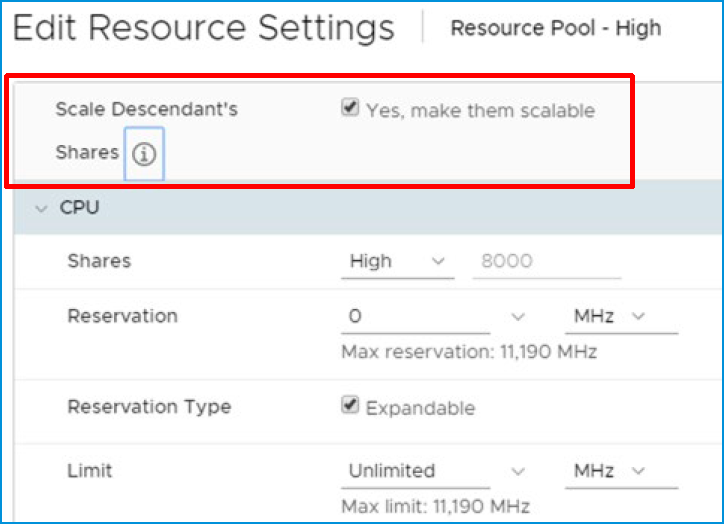
With the addition of the scalable shares functionality, a “high” share will be really high, relative to other entities in the same branch, that have a lower share.
It is not turned on by default, but it can be set on a cluster level:
And on a resource pool level:
vMotion Improvements
When DRS (or an operator) decides that a virtual machine must be moved to another host, it will be done through vMotion. This has been around a very long time while the size of virtual machines has increased a lot.
What vMotion does is copy over memory from one host to another. During the process of copying memory, memory is changed, so after the first copy, vMotion copies the changed memory. Again, when doing this, memory is changed… This process continues until the last piece of memory can be copied. When this moment occurs, the virtual machine is “stunned” (paused), the last piece of changed memory is copied and the virtual machine is resumed on the new host.
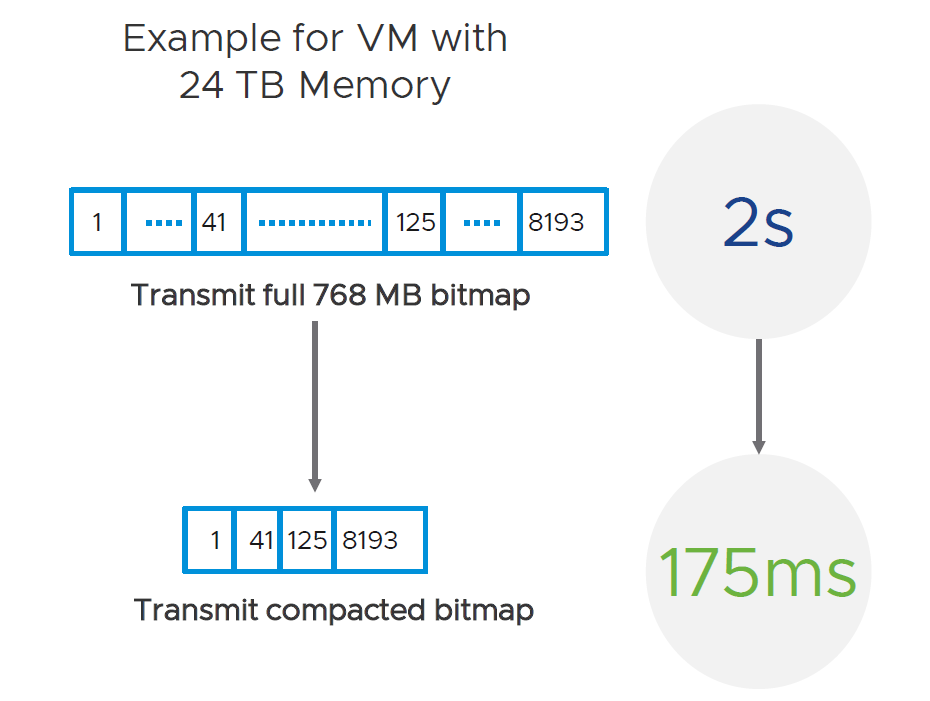
Because the amount of memory in virtual machines has increased in the years since vMotion first came into existence, the last piece of memory becomes larger and larger. This is because the memory is split into chunks (bitmaps) that increase when more memory is assigned to a virtual machine. vMotions copies over the whole bitmap when it has changed.
With virtual machines of 24 TB (not currently supported, but who knows what the future holds), this would mean that the last bitmap would be 768 MB large. Transferring this over the network would take some time, leading to (with the current vMotion methodology) to a stun time of two seconds. This could lead to application issues. So with the new methodology, vMotion uses compact bitmaps (with only the real changes), which would cut down the time needed to copy over the last bitmap from two seconds to 175 milliseconds.
Compute enhancements
With the new version of vSphere, the ability to use the newest Intel and AMD CPU’s as an EVC-mode is possible. It supports Intel Cascade Lake and AMD Zen 2 Generation cpu’s.
Virtual Machine version will be 17, with a couple of enhancements there as well. For instance a watchdog timer, which can be used to determine if a virtual machine is in a hung or crashed state and needs to be restarted.
Also added in virtual hardware version 17 is a precision clock, which will have sub-millisecond accuracy, which might be useful for financial and scientific applications.
So, all in all, I would say that vSphere 7 is both a revolution (if you are looking for integration with Kubernetes) and an evolution, with lots of large and small changes to the inner workings of the product. I am impressed with what VMware has come up with.
2 thoughts on “vSphere 7 and VCF 4.0: evolution or revolution?”