Anti Affinity policy shows “Pending” on Prism Central
I received a question from a customer. There were some issues with anti-affinity rules in their environment, where the status would stay on “Pending”, after they had created an anti-affinity rule for VM’s. In my lab-environment I tried this out as well and, at first, ran into the same issue.
This is my environment:
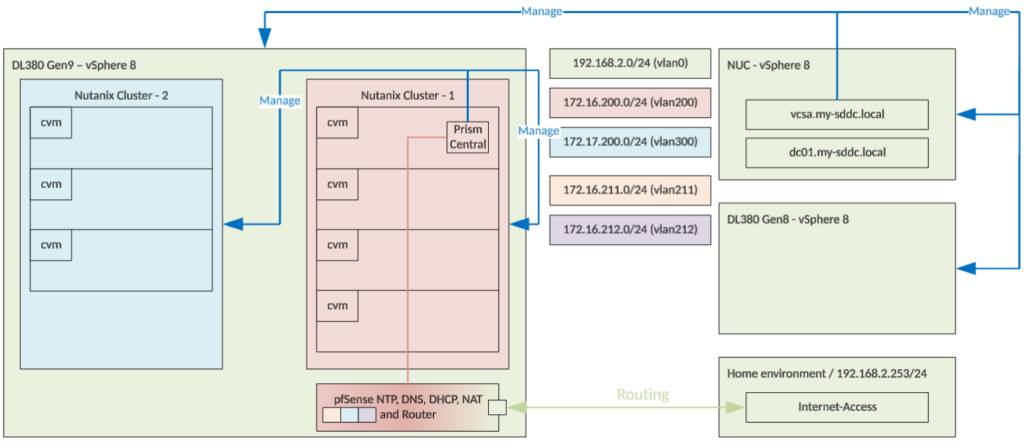
As you can see, I have two clusters, connected to one Prism Central. I usually have my lab shut down and power it on, when needed. When that is the case, I usually try to not use too many resources, so If I can use one of the clusters, for my tests, that is perfectly fine. And that is relevant here.
So what I did was the following (for two VMs):
- Power on Nutanix Cluster – 1 and all required VM’s, like Prism Central and pfSense
- Power on Linux based Guest VM’s
- Move VM’s to the same host for two VM pairs
- Create a category
- Assign category to VM’s
- Create an Anti-Affinity Policy, with the created category
- Waited for (at least) half an hour (two ADS cycles)
And I did this twice, once as an AD-based user, with Super Admin permissions and once with the Admin account itself. I used one pair of VM’s per policy.
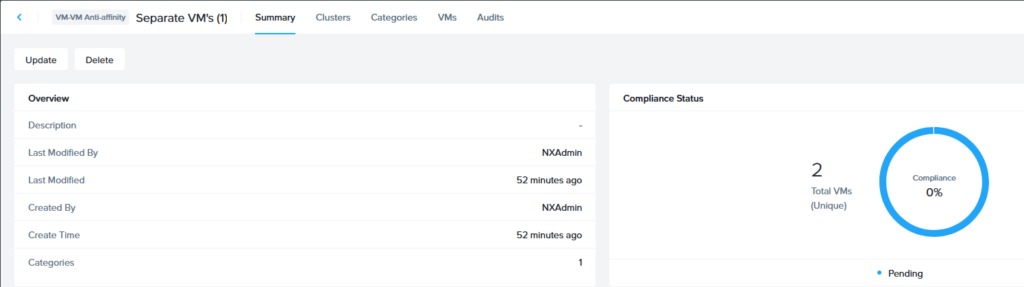
After all that, I found that the Anti Affinity policy stayed on “Pending”, like so, even after waiting for a long time:

Then I tried to find some answers. In one of the internal slack-posts I found around a similar issue, I was refered to a KB-article: https://portal.nutanix.com/page/documents/kbs/details?targetId=kA0VO000000BA450AG.

Which did more or less describe my issue, but I am not using any firewalls. However, I did see log entries like this:
E0113 08:39:04.494000Z 228621 vmm_error.go:1956] vm-anti-affinity-policies/v4_list_legacy_vm_anti_affinity_policy.go:248 Failed to get supported clusters for anti-affinity policy: Error occurred in trying to get Anduril capabilities: Error in sending RPC: 103This more or less led me in the direction of the second cluster. So I powered on the second cluster and after that was completed, the Policy first moved to:
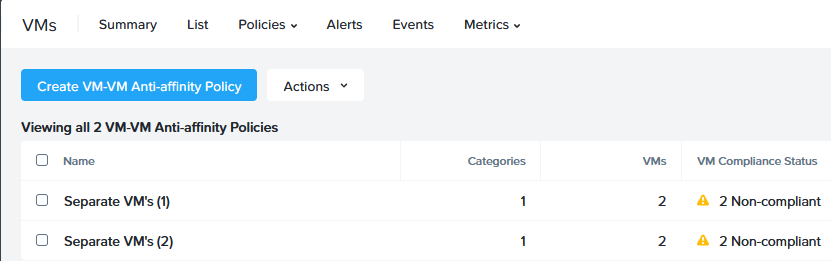
and after two of the VM’s were placed on different hosts, to:
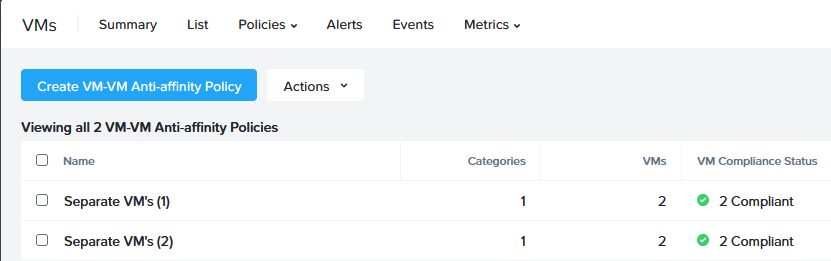
After resolving this, I shut down the second cluster again, remove the policies, recreate the policies and see if that would recreate the problem. It did, althoug this time I got a different entry in the log-file:
10:29:06.919091Z 228621 vmm_error.go:1956] vm-anti-affinity-policies/policy_engine_apply_task.go:198 7ddf0a50-4e93-52a8-b36a-baf7d5c42444: Failed to CreateOrUpdateVmGroupWithAntiAffinity through Narsil at a cluster with UUID 000640c9-e04b-4b7a-71c7-005056a52cdf: rpc error: code = Unavailable desc = last connection error: connection error: desc = "transport: Error while dialing: dial tcp 172.17.200.103:2121: i/o timeout".Which seems to indicate that this time it does know where to connect, but just can’t, while at first it didn’t know where to connect. Small distinction, but identical results.